AIGC是什么,与AI绘画有什么关系,一篇文章带你了解AI绘画的前世今生

AI历史发展轨迹
什么是人工智能
人工智能(Artificial intelligence,简称AI)亦称机器智能,指由人制造出来的机器所表现出来的智能。通常人工智能是指用普通计算机程序来呈现人类智能的技术。是计算机科学的一个重要分支,是一门寻求模拟、扩展和增强人的智能的科学和技术领域,涉及计算机科学、心理学、哲学、神经科学、语言学等多个学科。人工智能的主要目标是使计算机或其他设备能够执行一些通常需要人类智慧才能完成的任务,如学习、理解、推理、解决问题、识别模式.处理自然语言、感知和判断等。
人工智能的发展可以分为两大类–弱人工智能(Weak AI)和强人工智能(Strong AI)。弱人工智能是指专门设计用来解决特定问题的智能系统,如语音识别、图像识别和推荐系统等。这些系统在某些特定任务上表现出高度的智能,但它们并不具备广泛的认知能力或自主意识。
强人工智能则是指具有广泛认知能力和类人意识的智能系统,这种系统理论上可以像人类一样处理各种问题,独立地学习和成长。然而,尽管人工智能领域已经取得了显著的进展,但目前尚未实现强人工智能。
发展历史

总体来说,人工智能的发展可以分为四个阶段。
1 早期研究(20世纪50年代-60年代)
第一个阶段,科学家们集中精力研究基本的人工智能概念和理论。代表性成果包括图灵测试、第一个人工智能程序(逻辑理论家)以及人工神经网络的基础研究。
2 知识表示与专家系统(20世纪70年代-80年代)
第二个阶段,研究重心转向利用知识表示、推理和规划技术,解决更复杂的问题。其间涌现出大量基于知识的专家系统,如早期的医疗诊断系统MYCIN。
3 机器学习与统计方法(20世纪90年代-21世纪初)
第三个阶段,人工智能领域开始广泛应用机器学习技术,尤其是统计学习方法。代表性技术包括支持向量机(SVM)、随机森林以及早期的深度学习方法。
4 大数据与深度学习(21世纪10年代一至今)
随着大数据的兴起和计算能力的提高,深度学习技术取得了突破性进展。诸如卷积神经网络(CNN)、循环神经网络(RNN)以及强化学习等领域取得了重要成果。这一阶段的人工智能已在众多应用场景中取得了显著的成绩,如图像识别、自然语言处理和自动驾驶等。
AIGC是什么
"Artificial Intelligence Generated Content"的首字母缩写,即采用人工智能技术来自动生产内容,目前AIGC已经可以生成文章、代码、对话、图片、视频、音乐、表格等多种多样的内容,而且还在快速发展。
从技术能力方面来看,AIGC根据面向对象、实现功能的不同可分为三个层次。
一、智能数字内容孪生:
简单的说,将数字内容从一个维度映射到另一个维度。 因为另一个维度内容不存在所以需要生成。内容孪生主要分为内容的增强与转译。增强即对数字内容修复、去噪、细节增强等。转译即对数字内容转换如翻译等。
【应用】:图像超分、语音转字幕、文字转语音等。
二、智能数字内容编辑:
智能数字内容编辑通过对内容的理解以及属性控制,进而实现对内容的修改。比如不同场景视频片段的剪辑。通过人体部位检测以及目标衣服的变形控制与截断处理,将目标衣服覆盖至人体部位,实现虚拟试衣。在语音信号处理领域,通过对音频信号分析,实现人声与背景声分离。以上就是在理解数字内容的基础上对内容的编辑与控制。
【应用】:视频场景剪辑、虚拟试衣、人声分离等。
三、智能数字内容生成:
智能数字内容生成通过从海量数据中学习抽象概念,并通过概念的组合生成全新的内容。如AI绘画,文本创作、音乐创作和诗词创作。再比如,在跨模态领域,通过输入文本输出特定风格与属性的图像,不仅能够描述图像中主体的数量、形状、颜色等属性信息,而且能够描述主体的行为、动作以及主体之间的关系。
【应用】:图像生成(AI绘画)、文本生成(AI写作、ChatBot)、视频生成、多模态生成等。
以上三个层面的能力共同构成 AIGC的能力闭环。
从生成内容层面AIGC可分为五个方面:
1、文本生成
【代表性产品或模型】:JasperAI、copy.AI、ChatGPT、Bard、AI dungeon等。
2、图像生成
【代表性产品或模型】:EditGAN,Deepfake,DALL-E、MidJourney、Stable Diffusion,文心一格等。
3、音频生成
【代表性产品或模型】:DeepMusic、WaveNet、Deep Voice、MusicAutoBot等。
4、视频生成
【代表性产品或模型】:Deepfake,videoGPT,Gliacloud、Make-A-Video、Imagen video等。
5、多模态生成
【代表性产品或模型】:DALL-E、MidJourney、Stable Diffusion等。
AIGC相关技术
最近几年,生成算法、预训练模型、多模态等A技术累积融合,催生了AIGC 的大爆发。
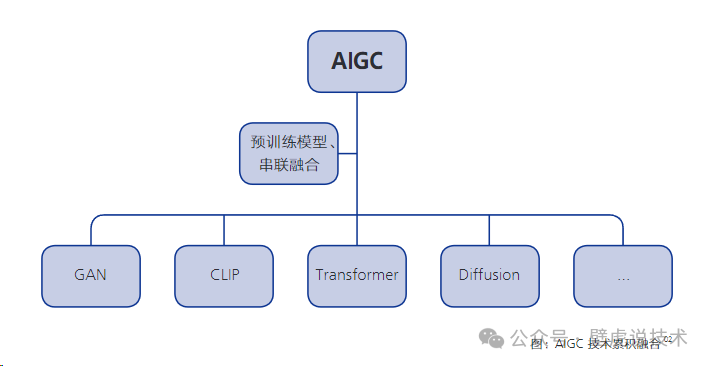
主要三方面:
一、基础的生成算法模型不断突破创新
基础的生成算法模型
二、预训练模型引发了AGC技术能力的质变
预训练模型
5400亿 110亿 200亿 | NLP NLP NLP 多模态 多模态 | | 微软 | Florence Turing-NLG | 视觉识别 语言理解、生成 | 6.4亿 170亿 | CV NLP | | Facebook | OPT-175B M2M-100 | 语言摸型 100种语言互译 | 1750亿 150亿 | NLP NLP | | Deep Mind | Gato Gopher AlphaCode | 多面手的智能体 语言理解与生成 代码生成 | 12亿 2800亿 414亿 | 多模态 NLP NLP | | Open AI | GPT3 CLIP&DALL-E Codex ChatGPT | 语言理解与生成、推理等 图像生成、跨模态检索 代码生成 语言理解与生成、推理等 | 1750亿 120亿 120亿
| NLP 多模态 NLP NLP | | 英伟达 | Megatron- Turing NLG | 语言理解与生成、推理 | 5300亿 | NLP | | Stability AI | Stable Diffusion | 语言理解与图像生成 | – | 多模态 |
三、多模态技术推动了 AIGC的内容多样性,让 AIGC具有了更通用的能力。
预训练模型更具通用性,成为多才多艺、多面手的 A 模型,主要得益于多模型技术(multimodal technology)的使用,即多模态表示图像、声音、语言等融合的机器学习。2021年,OpenAl 团队将跨模态深度学习模型CLIP(Contrastive Language-lmage Pre-Training,以下简称“CLIP”)进行开源。CLIP 模型能够将文字和图像进行关联,比如将文字“狗”和狗的图像进行关联,并且关联的特征非常丰富。
在多模态技术的支持下,目前预训练模型已经从早期单一的 NLP 或 CV模型,发展到现在语言文字、图形图像、音视频等多态、跨态模型。
AI绘画
通过上面的介绍,我们知道了AI绘画只是AIGC的一部分内容(图像生成相关领域)。
AI绘画(Artificial Intelligence Painting)指的是应用人工智能技术生成绘画作品。这项技术的产生源于计算机科学、神经网络和机器学习等领域的发展。最早的计算机生成技术可以追溯到20世纪50年代,近年来的发展则主要归功于深度学习技术的进步以及硬件性能的提升。
从原理上来说,现代AI绘画技术主要是通过神经网络大量学习艺术作品的风格和特征,最后将所学的元素和风格融合到新的作品中,从而创作出新的绘画作品。
发展历程
早期的计算机绘画尝试
1965年,纳克发布了一幅由计算机程序生成的画作,名为《向保罗·克利致敬》(Hommage à Paul Klee)(如图下图所示)。

哈罗德·科恩(Harold Cohen)是一位英国艺术家,曾代表英国参加1966年的威尼斯双年展。1968年,他成为加州大学圣地亚哥分校的客座教授,在那里他接触到了计算机编程。1971年,他向秋季计算机联合会议展示了一个初步的绘画系统原型,并因此受邀以访问学者的身份前往斯坦福人工智能实验室,1973年,他在那里开发了名为AARON的计算机绘画程序。下图为科恩的两幅作品。


到后面1980年,本诺伊特·曼德尔布罗创作的图片:

同时计算机技术不停发展,到20世纪80年代至90年代,神经网络和机器学习技术的出现,为计算机绘画的发展带来了新的可能性,这些技术允许计算机通过学习大量数据来模拟人类大脑的工作方式,从而在一定程度上实现智能绘画。
新技术的发展(21世纪10年代)
2012年,AlexNet的深度卷积神经网络(Convolutional Neural Network, CNN)的算法出现在绘图上取得不错效果。 AlexNet主要应用于计算机视觉领域,特别是图像分类任务。然而,它的成功也对AI绘画领域产生了深远影响,许多研究人员受到启发,开始探索AI在视觉艺术领域的潜力,为后续研究和应用奠定了基础。
到2014年,生成对抗网络(GenerativeAdversarial Networks, GAN),被认为是过去20年人工智能历史上最大的进步。AI领域杰出人物、百度前首席科学家吴恩达曾如此评价:GAN代表着“一项重大而根本性的进步”。
GAN取得了前所未有的突破,经过良好训练的GAN能生成非常高质量的新图像,这些图像对于人类观察者来说极 具真实感,几乎无法区分是真实图像还是AI生成的图像。正是因为如此,这个算法一度成为AI绘画的主流研究方向。
下图为GAN生成图像:

2016年,一个名为扩散模型(Diffusion Models)的新方法被提出,它的灵感来自非平衡统计物理学,通过研究随机扩散过程来生成图像。如果可以建立一个学习模型来学习由于噪声引起的信息系统衰减,那么也可以逆转这个过程,从噪声中恢复信息。简单来说,扩散模型的原理为:首先向图片添加噪声(正向扩散),让算法在此过程中学习图像的各种特征,然后,通过消除噪声(反向扩散)来训练算法恢复原始图片。这种方法与GAN的思路截然不同,它很快便在图像生成。
下图为扩散模型从噪声生成图片的过程:

现代AI绘画(21世纪20年代)
DALL·E 2
2020年,OpenAI推出了具有突破性的深度学习算法CLIP(Contrastive Language-Image Pretraining,对比语言—图像预训练)。这一算法在人工智能领域产生了深远影响,对人工智能艺术的发展也带来了重大变革。CLIP将自然语言处理和计算机视觉相结合,能够有效地理解和分析文本与图像之间的关系,例如把“猫”这个词和猫的图像联系起来,这就为构建基于文本提示进行艺术创作的AI提供了可能。
2021年,OpenAI推出了名为DALL·E的产品,它能根据任意文字描述生成高质量图像。在此之前,虽然已经存在许多神经网络算法能够生成逼真的高质量图像,但这些算法通常需要复杂精确的设置或者输入,相较之下,DALL·E通过纯文本描述即可生成图像,这一突破性的改进极大降低了AI绘画的门槛,并迅速成为流行的标准。
Imagen
2022年4月,就在DALL·E 2发布之后不久,谷歌发布了基于扩散的图像生成算法Imagen,也是一个通过文字生成图像的工具。
Stable Diffusion
2022年7月,一家创始于英国的名为StabilityAI的公司开始内测他们所开发的AI绘画产品Stable Diffusion,这是一个基于扩散模型的AI绘画产品。人们很快发现,它生成的图片质量可以媲美DALL·E 2,更关键的是,内测不到1个月,Stable Diffusion就正式宣布开源,这意味着如果有计算资源,就可以让Stable Diffusion在自己的系统上运行,还可以根据自己的需求修改代码或者训练模型,打造专属的AI绘画工具。
Midjourney
Midjourney是由同名公司开发的另一种基于扩散模型的图像生成平台,于2022年7月进入公测阶段,面向大众开放。与大部分同类服务不同,Midjourney选择在Discord平台上运行,用户无须学习各种烦琐的操作步骤,也无须自行部署,只要在Discord中用聊天的方式与Midjourney的机器人交互就能生成图片。
AI绘画工具
目前AI绘画快速发展,国内外都出现了许多免费和服务的平台,如下:
国外
国内
1.泛类AI绘画产品
2.垂类绘画产品
到此AI绘画相关的历史基础介绍完了。
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。 
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手! 
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。 

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。 
本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:975644476@qq.com
本文链接:http://chink.83seo.com/news/7600.html








最新文章
-

微信号解绑手机号(微信号解绑手机号后手机号还能再注册)
2025-12-15 -

华为哪一款手机好(华为哪一款手机好一点又便宜)
2025-12-15 -

二手手机代理(二手手机代理平台 一件代发)
2025-12-15 -

卖假手机怎么处罚(卖假手机算不算诈骗)
2025-12-15 -

如何锁苹果手机(如何锁苹果手机相册)
2025-12-15 -

手机移动版什么意思(手机移动版是只能用移动卡吗)
2025-12-15 -

华为手机丢失如何清除数据(华为手机丢失如何清除数据记录)
2025-12-15 -

oppo手机闪屏怎么办(oppo手机闪屏怎么回事?)
2025-12-15
热门文章
-

百度投放广告一天多少钱?怎么投放效果好?
2024-12-11 -

开业广告文案
2024-12-27 -

如何将店铺上传到百度地图?如何将店铺地址上传到百度地图?
2024-12-07 -

百度搜索推广每年的费用是多少?百度搜索推广的收费准则是怎样的?
2024-12-07 -

电信手机推荐(电信手机哪款好用价格又不贵)
2025-01-17 -

淘宝新品应该如何做推广?淘宝推广新品有哪些窍门?
2024-12-20 -

什么是IT行业? IT行业都有哪些职位?
2025-04-14 -

产品运营推广全流程解析:从定位到推广
2024-12-19